
LLMs serão 100 vezes mais eficientes e 90% mais baratos em 2030, diz Gartner

Grandes Modelos de Linguagem (LLMs) em 2030 serão até 100 vezes mais eficientes em termos de custo do que os primeiros modelos de tamanho semelhante desenvolvidos em 2022. A previsão é do Gartner, que estima que realizar inferências em LLM com 1 trilhão de parâmetros terá redução de custos de mais de 90% em 2030 em relação a 2025 aos provedores de IA generativa.
Os tokens de IA são as unidades de dados que os modelos de IA generativa processam. Para os fins desta análise, um token corresponde a 3,5 bytes de dados, ou aproximadamente 4 caracteres. De acordo com Will Sommer, diretor-analista-sênior do Gartner, “essas melhorias de custo serão impulsionadas por uma combinação de avanços na eficiência de semicondutores e infraestrutura, inovações no design de modelos, maior utilização dos chips, aumento do uso de silício especializado para inferência e aplicação de dispositivos de borda (edge) para casos de uso específicos”.
Como resultado dessas tendências, o Gartner prevê que os LLMs em 2030 serão até 100 vezes mais eficientes em termos de custo do que os primeiros modelos de tamanho similar desenvolvidos em 2022. Os resultados projetados são divididos em dois conjuntos de cenários de semicondutores.
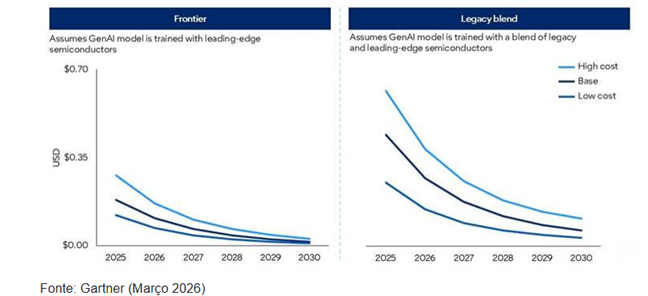
Nos cenários de ponta (frontier), o processamento do modelo é baseado em uma representação de chips de ponta. Já nos cenários de combinação legada (legacy blend), o processamento do modelo é baseado em uma combinação representativa de semicondutores disponíveis, referenciada às previsões do Gartner.
Os custos modelados nos cenários de previsão de “combinação” são consideravelmente mais elevados do que nos cenários de “ponta”, devido à menor capacidade computacional.
No entanto, o Garnet alerta que a queda nos custos por tokens dos provedores de GenAI não será totalmente repassada aos clientes corporativos e que a inteligência de ponta exigirá significativamente mais tokens do que as aplicações convencionais atuais.
Os modelos agênticos, por exemplo, exigem de cinco a 30 vezes mais tokens por tarefa do que um chatbot de GenAI padrão e podem executar muito mais tarefas do que um humano usando IA Generativa.
Embora a redução dos custos unitários dos tokens possibilite recursos de GenAI mais avançados, essas melhorias impulsionarão uma demanda desproporcionalmente maior por tokens. Como o consumo de tokens cresce mais rápido do que a queda de seus custos, espera-se que os custos gerais de inferência aumentem.
Sommer aponta que os líderes de produtos — chief product officers (CPOs) — não devem confundir a deflação de tokens básicos com a democratização do raciocínio de ponta. Ele explica que, “à medida que a inteligência comoditizada se aproxima de um custo próximo de zero, a capacidade computacional e os sistemas necessários para suportar o raciocínio avançado permanecem escassos. Os CPOs que mascararem ineficiências arquitetônicas com tokens baratos hoje descobrirão que a escalabilidade agêntica será difícil de alcançar amanhã”.
O valor será gerado pelas plataformas capazes de orquestrar cargas de trabalho em um portfólio diversificado de modelos. Tarefas rotineiras e de alta frequência devem ser direcionadas para modelos de linguagem pequenos e específicos de domínio, que apresentam melhor desempenho do que soluções genéricas por uma fração do custo quando alinhados a fluxos de trabalho especializados. A inferência dispendiosa de modelos de ponta deve ser rigidamente controlada e reservada exclusivamente para tarefas de raciocínio complexas e de alta margem de lucro.
